ボットによるクロールを制御する方法
概要
本ページで説明するボットとは、インターネット上を巡回してサイトのデータを収集し、
検索エンジンに反映する「クローラー(別称:スパイダー)」のことを指します。
ボットが収集したデータは、googleやBing(またはその他)の検索エンジンで検索結果をユーザーに提供するため、
SEO対策においてボットは大変重要な存在です。
しかしながら日本国外で利用される一部の検索エンジンによるボットや、
セキュリティ上悪意をもったボットの存在はPV数の増加を招くため、
状況によってはサイト全体へのクロールを制御する必要があります。
本システムでボットによるクロールを制御する方法は、以下の3通りです。
店舗様のご状況に応じて、必要な対策を講じてください。
1.すべての検索エンジンからのアクセスをブロックしたい
2.特定の検索エンジンからのアクセスをブロックしたい
3.特定のIPアドレスのみアクセスをブロックしたい
サイト全体ではなく、一部のぺージのみを検索結果に表示させたくない場合についてはこちらをご覧ください。
1.すべての検索エンジンからのアクセスをブロックしたい
1.『robots.txt』を用意する
テキストエディタなどで、以下のように記述したrobots.txtのファイルを用意します。
■robots.txt 記述例
User-agent: *
Disallow: /
『robots.txt』とは、検索エンジンのクローラーを制御するためのテキストファイルです。
クローラーのアクセス頻度を指定したり、アクセスを拒否することができます。
(検索エンジンによっては、命令を無視してクロールされる場合もあります)
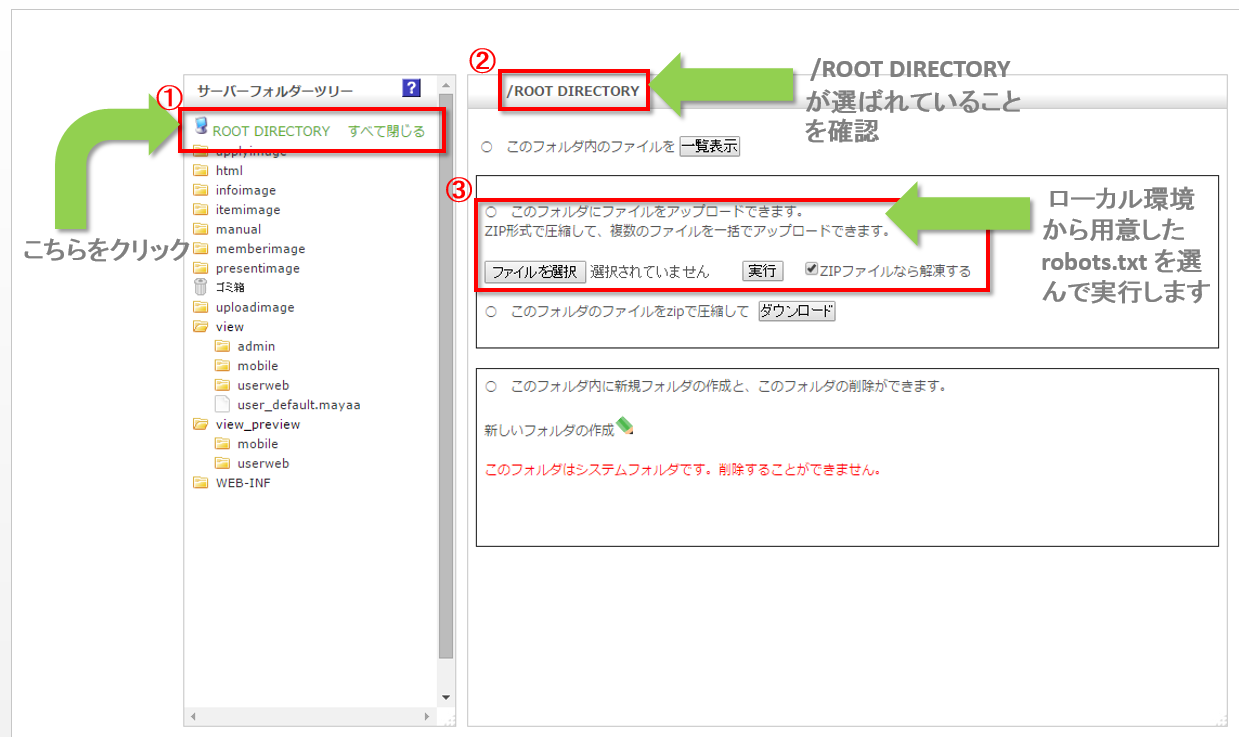
2.『robots.txt』をショップ管理ツールにアップロード
ショップ管理ツールにて『robots.txt』を『ROOT DIRECTORY』直下にアップロードしてください。
アップロードは「テンプレート管理」画面から行います。
「テンプレート管理」画面へのアクセス
下記の順でグローバルナビゲーションからアクセスしてください
![]() → 「テンプレート管理」
→ 「テンプレート管理」
アップロードした『robots.txt』の挙動が正しいかを確認したい場合は、
googleサーチコンソールの「robots.txtテスター」をご利用ください。
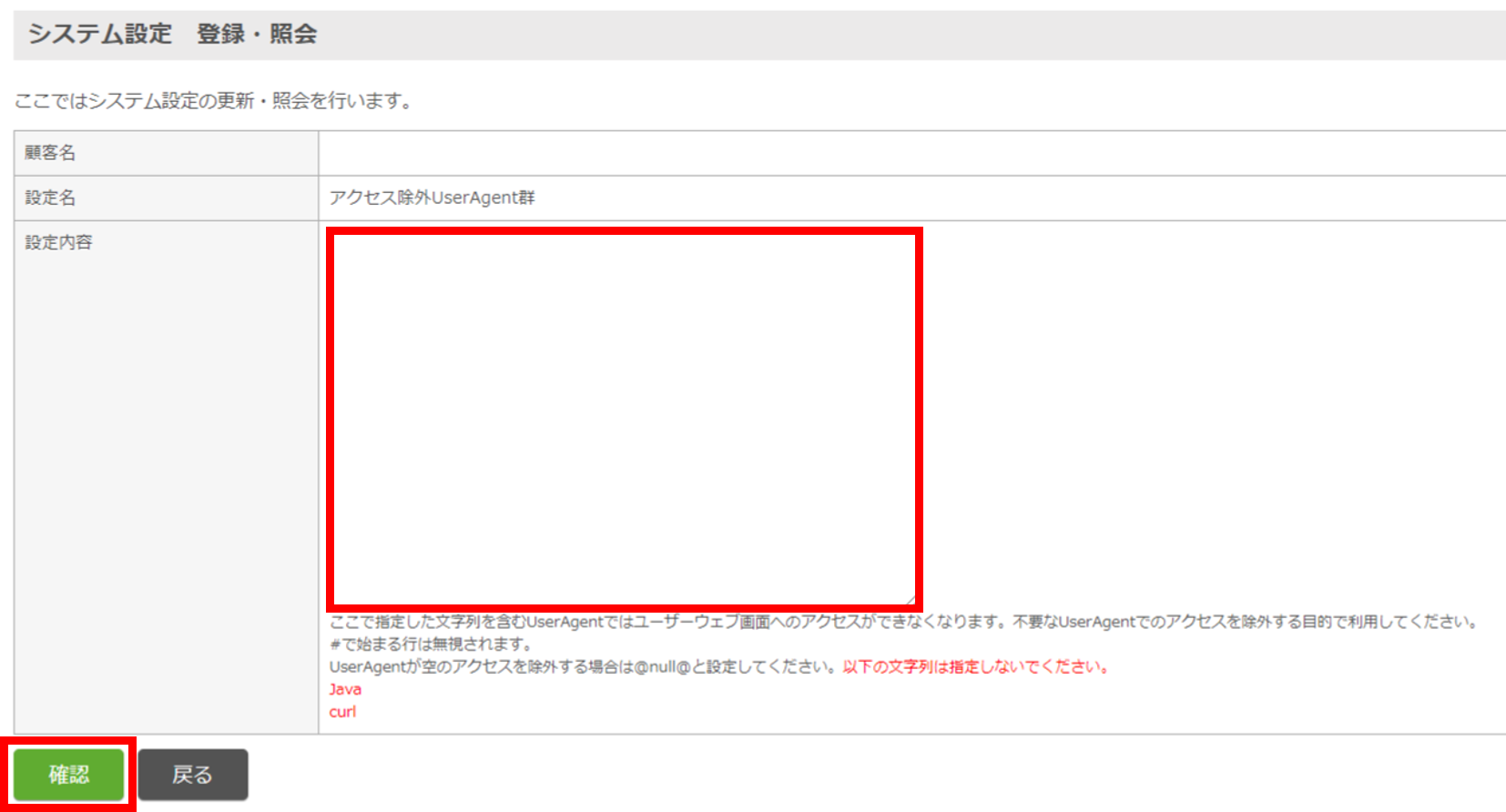
2.特定の検索エンジンからのアクセスをブロックしたい
初期設定「アクセス除外UserAgent群」を設定
下記の順でグローバルナビゲーションからアクセスしてください。
![]() → 「システム設定マスタ」 → 「初期設定」→「アクセス除外UserAgent群」
→ 「システム設定マスタ」 → 「初期設定」→「アクセス除外UserAgent群」
「アクセス除外UserAgent群」にブロックしたい不要な検索エンジン等のUserAgentを、改行区切りで登録してください。
※大文字小文字の区別はありません。
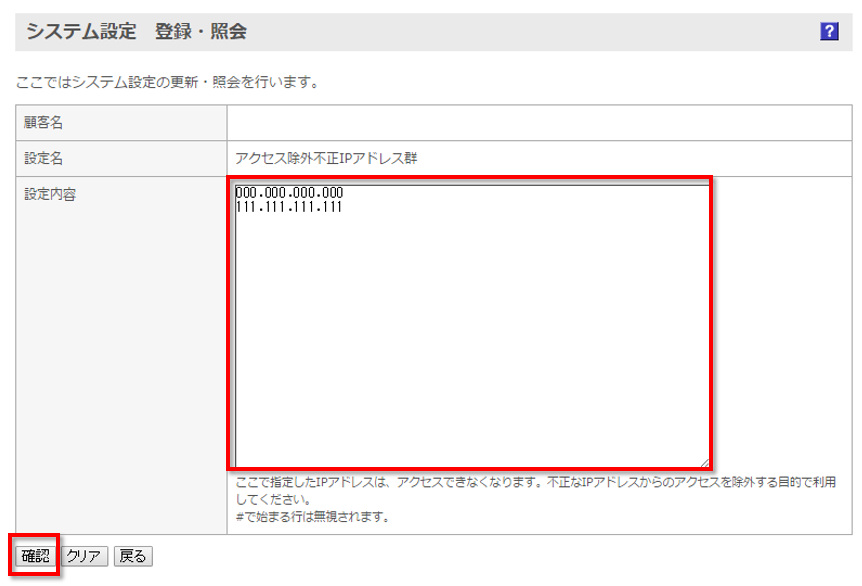
3.特定のIPアドレスのみアクセスをブロックしたい
初期設定「アクセス除外不正IPアドレス群」を設定
下記の順でグローバルナビゲーションからアクセスしてください。
![]() → 「システム設定マスタ」 → 「初期設定」→「アクセス除外不正IPアドレス群」
→ 「システム設定マスタ」 → 「初期設定」→「アクセス除外不正IPアドレス群」
ブロックしたいアクセス元のIPアドレスを改行区切りで記入して登録してください。